
What is a Kubernetes Operator?
A Kubernetes Operator is a method of packaging, deploying, and managing a Kubernetes application. It extends the native Kubernetes API by combining custom resources (CRDs) with a dedicated controller: a custom control loop that continuously watches the state of those resources.
The primary purpose of an operator is to automate complex, stateful applications (like databases, message queues, or monitoring suites) that require human operational knowledge to maintain. Instead of a human engineer manually executing tasks like backups, upgrades, or failure recovery, the operator encapsulates this domain-specific logic directly into code, automatically reconciling the actual state of the cluster with the desired state declared by the administrator.
What is Kubernetes Resource Optimization?
Kubernetes Resource Optimization is the continuous process of analyzing, adjusting, and rightsizing the CPU and memory allocations assigned to containerized workloads. By default, developers often over-provision container resource requests and limits to prevent performance bottlenecks or out-of-memory (OOM) kills, which leads to massive resource waste and inflated cloud infrastructure bills.
Optimization platforms such as Kubex bridge this gap by analyzing historical and real-time telemetry data, such as peak utilization, throttling, and memory patterns. Based on these metrics, the platform dynamically calibrates container specs to match actual runtime behavior. This optimization can be done manually via recommendations, or automated entirely using Kubex’s policy-driven automation engine, which incorporates extensive safety checks, to streamline performance and minimize infrastructure costs.
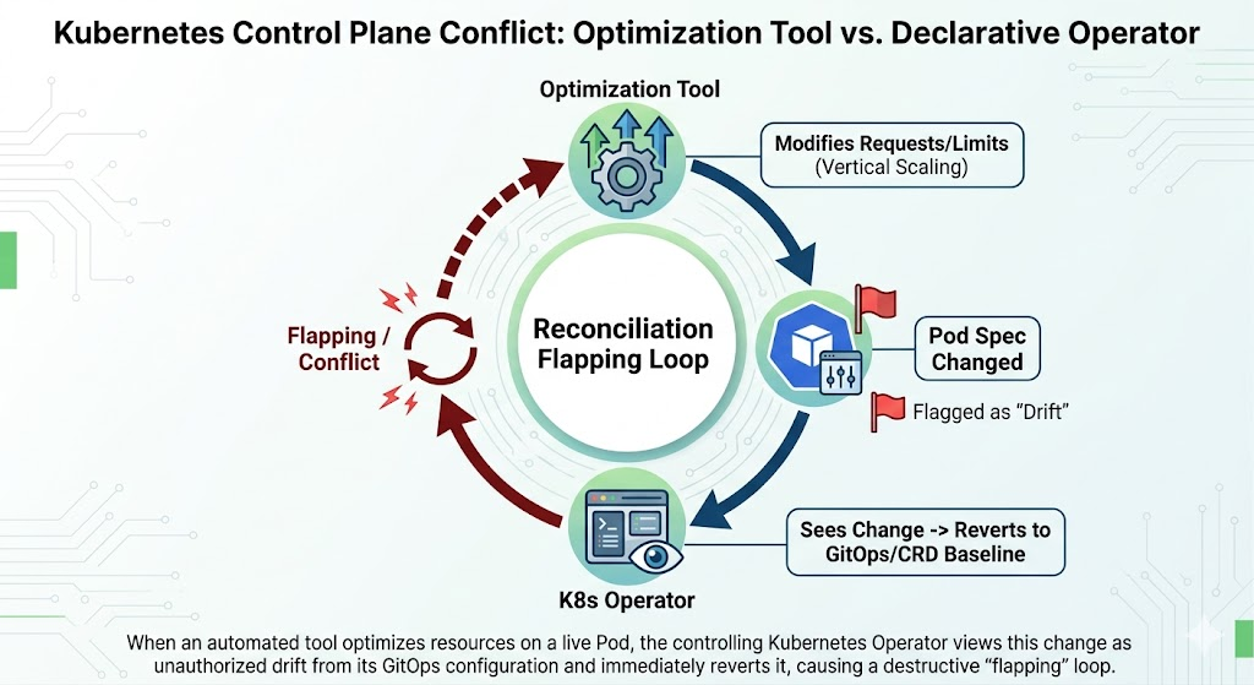
The Mechanism of the Conflict
Kubernetes operators and Resource Optimization tools both operate on a Reconciliation Loop (Desired State vs. Actual State). When they watch the same parameters, there is a possibility for conflict.
Here is exactly how that conflict manifests:
- The Operator’s Perspective: An operator manages an application via a Custom Resource Definition (CRD). It expects the Pod specification, including CPU and memory requests/limits, to match exactly what is defined in its code or Git repository.
- The Optimizer’s Perspective: Resource optimization tools like Kubex continuously analyze live utilization metrics and dynamically update container requests/limits to right-size the workload and save costs.
- The Conflict (Flapping): The optimization tool updates a deployment’s resource requests. The operator detects this change, flags it as configuration drift, and immediately overwrites it back to the original baseline. This creates an infinite loop of updates and reverts, causing CPU churn in the control plane and potential pod eviction cycles.
Operators Prone to Conflicts
Here are some operators that can trigger these reconciliation conflicts:
- CloudNativePG (PostgreSQL): This operator manages PostgreSQL clusters natively by continuously reconciling its Cluster CRD down to the underlying StatefulSet and Pods. If an optimization tool tweaks memory or CPU requests, CNPG views it as configuration drift and immediately attempts to revert it.
- Percona Operators (MySQL / MongoDB / PostgreSQL): Highly prescriptive about resource sizing to ensure database high availability, Percona’s operators actively reconcile live Pod specifications back to their custom resource definitions, overriding external changes.
- ECK (Elastic Cloud on Kubernetes): The official Elasticsearch operator is highly sensitive to memory settings due to JVM heap sizing and cgroups. ECK strictly reconciles node specifications; external mutations to memory settings will cause the operator to fight back, often causing pod disruption.
- OpenShift Operators: Many native Red Hat OpenShift operators (such as those managing cluster logging, service mesh, or internal monitoring) enforce highly strict out-of-the-box resource configurations. They are engineered to maintain a rigidly controlled environment and will actively overwrite external resource mutations to guarantee platform stability.
- IBM Cloud Pak Operators: Built with low-tolerance reconciliation loops to ensure enterprise compliance and predictable behavior, these operators prevent cluster administrators or external tools from drifting from tested, vendor-supported resource configurations.
- In-House Custom Operators: The biggest offenders are often home-grown operators built with Operator SDK or Kube Builder. A common design flaw is to “deep-equal” the entire desired Pod spec against the actual Pod spec during every sync loop. If the developer did not explicitly write logic to ignore changes to spec.containers[*].resources, the custom operator treats an optimized resource adjustment as unauthorized drift and triggers an aggressive loop of updates and restarts.
Why Pod-Level Mutation Avoids Flapping
Optimization tools like Kubex successfully mitigate flapping by utilizing a Mutating Admission Webhook to inject optimized resource values at the Pod level during creation. Because these tools modify the individual Pod spec rather than updating the parent Deployment or StatefulSet object, controllers that only monitor those higher-level abstractions remain completely oblivious to the change. As far as the high-level controller is concerned, its own manifest remains untouched, preventing drift detection from triggering a destructive update loop.
When Conflicts Arise
When an operator tightly couples its custom resources to runtime Pod specifications, the most reliable and non-intrusive solution is to disable automated patching within your Kubernetes optimization platform for those specific workloads or namespaces.
Optimization tools like Kubex allow you to enable or disable automated resource sizing at a granular level. You can apply this restriction at two distinct levels:
- Granular Exclusions (Workload Level): If only a specific database or component is managed by a strict operator, you can append a specific annotation to that deployment or statefulset template (for example, rightsizing.kubex.ai/pause-until: “2026-04-01T00:00:00Z”). The platform will continue to analyze telemetry and generate rightsizing suggestions, but it will never execute mutations on the API server for annotated workloads.
- Blanket Exclusions (Namespace Level): For large enterprise installations or database-heavy environments (such as a production-databases namespace), you can configure the optimization platform’s automation settings to entirely ignore or mute automated scaling policies for that namespace.
This hybrid approach allows platform engineers to maintain full automation across standard, stateless microservices while safely leveraging manual, human-approved recommendations or GitOps pull requests for sensitive, operator-managed stateful systems.
The Workaround Indicator: What to look for
If you are assessing whether an operator will fight with your optimization tool, look at its CRD schema.
If the operator forces you to define resources inside its own CR custom spec (e.g., postgres.spec.resources) rather than allowing you to manage the underlying Deployment/StatefulSet independently, it will almost certainly conflict with autonomous optimization tools unless the optimizer is explicitly configured to exclude that namespace or workload.
Conclusion
The intersection of Kubernetes Operators and autonomous Resource Optimization tools highlights a classic control plane challenge: the clash of competing reconciliation loops. While optimization platforms excel at dynamically rightsizing containers to reduce cloud spend and eliminate waste, their automated adjustments can easily look like unauthorized configuration drift to strict, top-down operators or GitOps controllers.
Resolving this tension doesn’t require abandoning automation. By shifting mutations downstream to the Pod level using mutating webhooks, utilizing GitOps-driven pull requests, or selectively disabling automation in favor of manual recommendations for sensitive, stateful namespaces, platform engineers can successfully balance the protective nature of operators with the efficiency of modern resource optimization.


