
Autonomous AI
Resource Optimization
Same hardware, same model, 3x the throughput.
Seven mechanisms, one continuous control loop.
Kubex observes utilization across every dimension that matters to AI inference, models the workload patterns, and acts on the cluster directly. Each capability below is part of the same control loop: they reinforce each other, rather than compete.
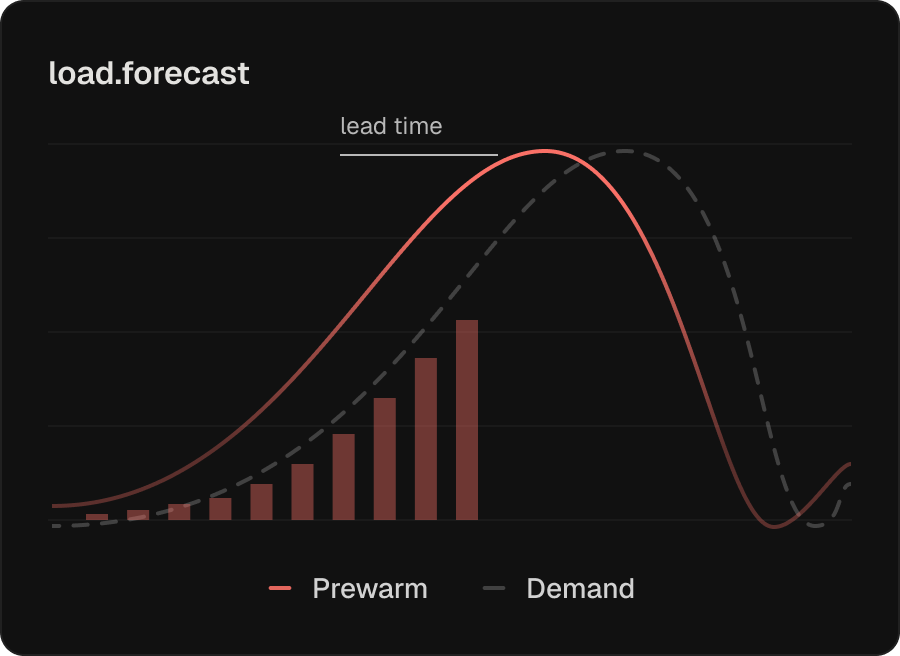
GPU Infrastructure Pre-Warming
Elastic GPU capacity is only useful if it’s warm when the request arrives. Cold-starting a GPU node (image pull, driver init, model load into VRAM) can add minutes of latency, right when requests start to time out.
- Node Prewarmer anticipates demand and brings GPU nodes up ahead of the curve, not in reaction to it
- Models pre-load into VRAM before traffic arrives, so the first request hits a hot path
- Same logic applies to CPU-bound services with non-trivial startup
- Result: scale-to-zero economics without the cold-start latency tax
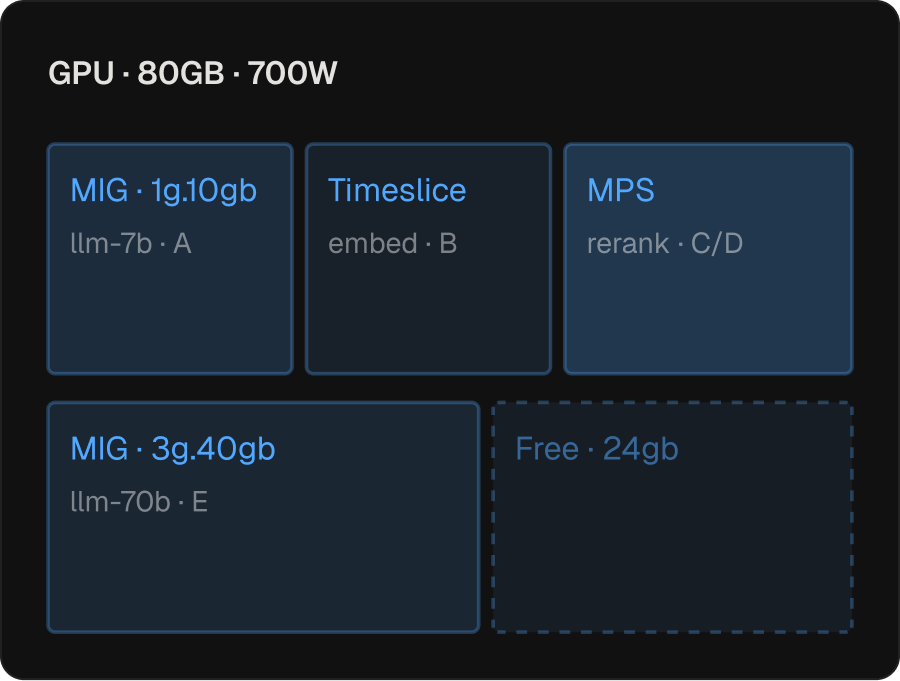
Performance-Optimized Fractioning
Optimizing GPU alone isn’t enough: a node out of ephemeral storage will starve its inference containers regardless of how much VRAM is free.
- Models utilization holistically across CPU, memory, ephemeral storage, network, GPU compute, GPU memory, and GPU power
- Recommends fractional sharing strategies and selects the right primitive per workload: timeslicing, MIG partitions, or MPS
- Targets the configuration where density and latency both improve, not maximum squeeze
- Net effect: concentrating jobs onto fewer, faster GPUs often lowers tail latency and raises yield together
Intelligent Scheduling & GPU Bin Packing
- Fractioning produces the shapes; scheduling places them
- Places each workload’s fraction profile in real time, allocating exactly what’s needed and filling existing nodes before adding new ones
- Fills gaps as workloads start and stop, keeping GPUs in their high-yield band
- Outcome: real downward elasticity as demand drops, preventing low-yield nodes from running up the bill

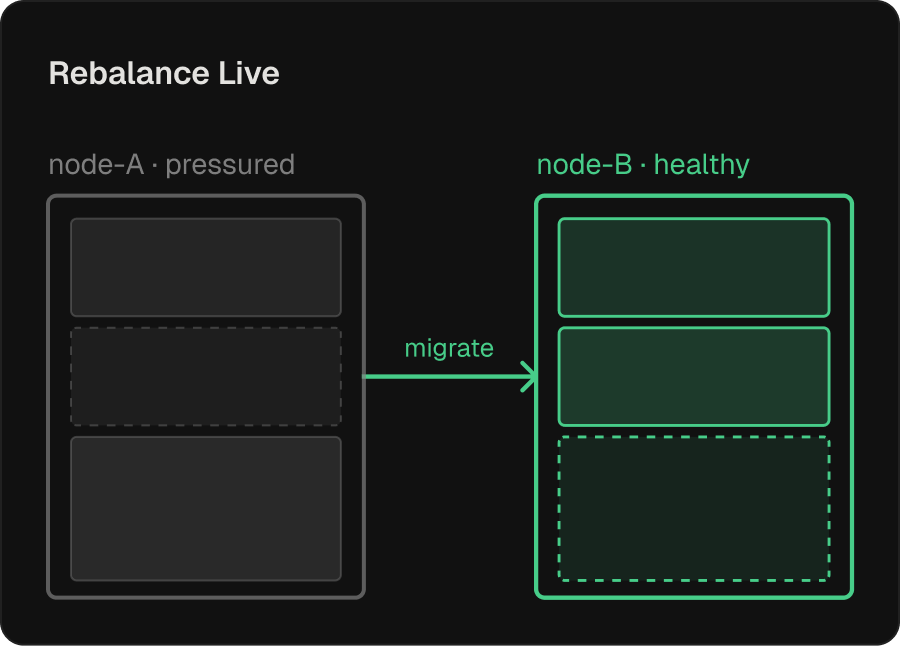
Dynamic Rebalancing
Workload shapes drift: a container that fits cleanly at 14:00 may be pressuring its neighbors by 14:30.
- Detects compute, memory, and GPU pressure and moves containers to nodes where they’ll perform, without waiting for the next deploy
- Rebalancing is the corrective action of a real-time control plane, not a periodic cron
- Payoff: this self-correction is what makes aggressive density and sharing safe to run
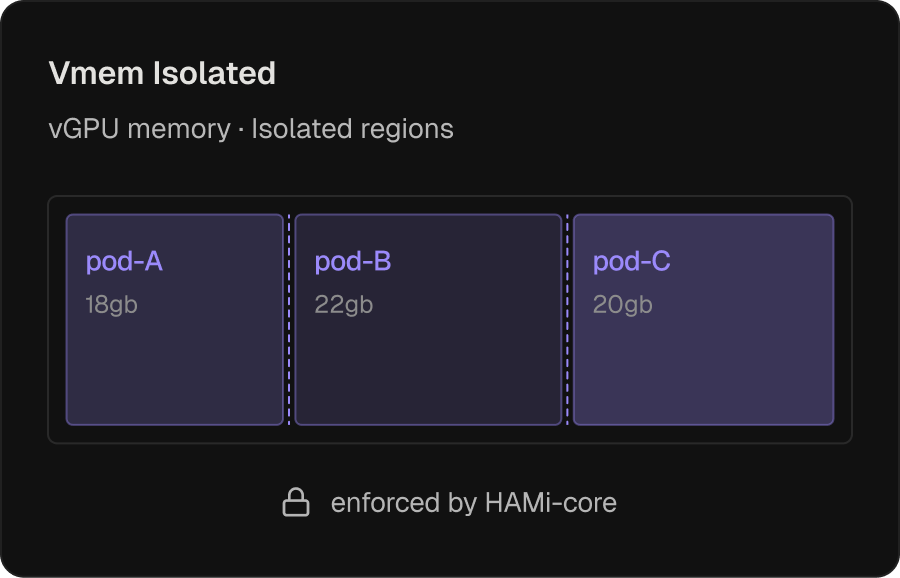
Memory Isolation
Timeslicing is the cheapest way to share a GPU, and the most dangerous: by default, neighboring workloads share a memory address space.
- HAMi-core enforces per-workload memory boundaries on top of timeslicing, so density doesn’t come at the cost of safety
- Combined with dynamic rebalancing, enables aggressive sharing for production AI services that previously needed one-pod-per-GPU
- Bottom line: noisy neighbors stay in their lane; an OOM in one container doesn’t take down the others
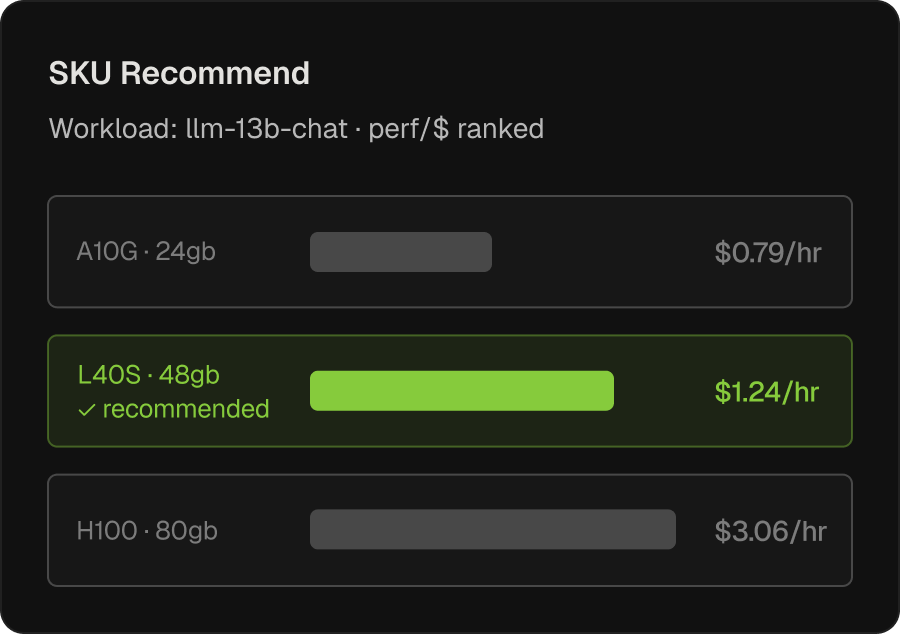
GPU SKU Optimization
GPU type and instance shape that’s cheapest for a workload today may not be the best fit next month, as fleet-level patterns shift.
- Continuously evaluates whether each workload is on the right GPU type and instance shape, within a given cloud
- Recommendations are grounded in the same multi-dimensional utilization data that drives fractioning
- Guardrail: lower spend is only recommended when performance is preserved or improved
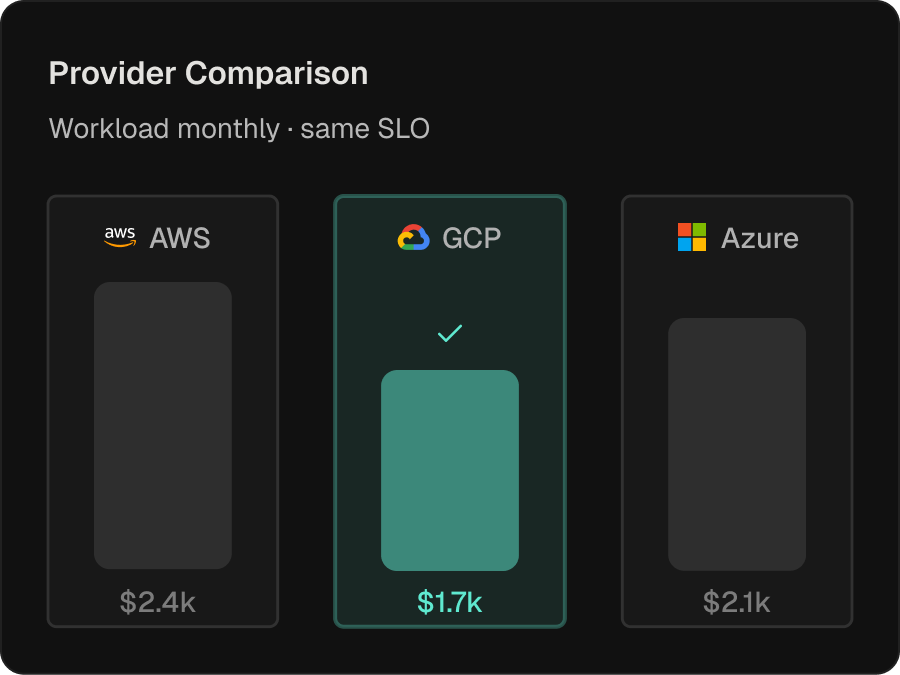
GPU Provider Optimization
- Extends the same comparative analysis across cloud providers, surfacing where a workload would run materially cheaper or faster elsewhere
- The output is signal grounded in measured utilization rather than list-price math; placement decisions remain the operator’s
- End result: feeds directly into the procurement and capacity-planning loop for multi-cloud and hybrid fleets
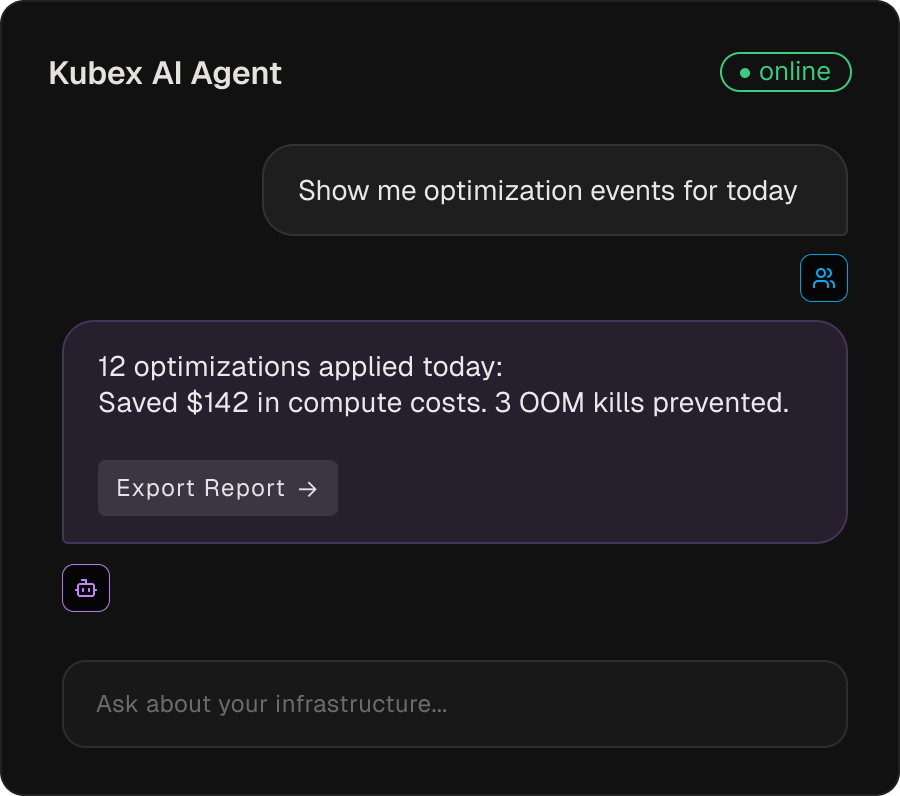
AI Agent
Brings optimization intelligence to wherever you work. Talk to Kubex in plain language, or connect your AI agents via MCP and make them infrastructure optimization experts.
Query your infrastructure in plain language and get direct, explainable answers about resource behavior, changes, and optimization decisions.
Connect Claude, Cursor, or any AI agent via MCP. You're not giving it raw data. You're making it an infrastructure optimization expert.
Grounded in deterministic AI, with private LLM integration. We don't train on your data.
Proven Results at Scale
See the measurable impact organizations achieve with our platform.
Rapid Cost Reduction
Toil Reduction
Reduction in OOM Kills
The Inference Throughput
See what Kubex can do in your own AI Inference Infrastructure
Same hardware, same model, 3x the throughput.