Resource optimization for AKS node pools and autoscalers.
Agent-driven optimization of pods, storage, autoscalers, and node fleets for AKS clusters backed by VMSS-based node pools or Karpenter — landing as Karpenter NodePool, Bicep / Terraform, or GitOps diffs.

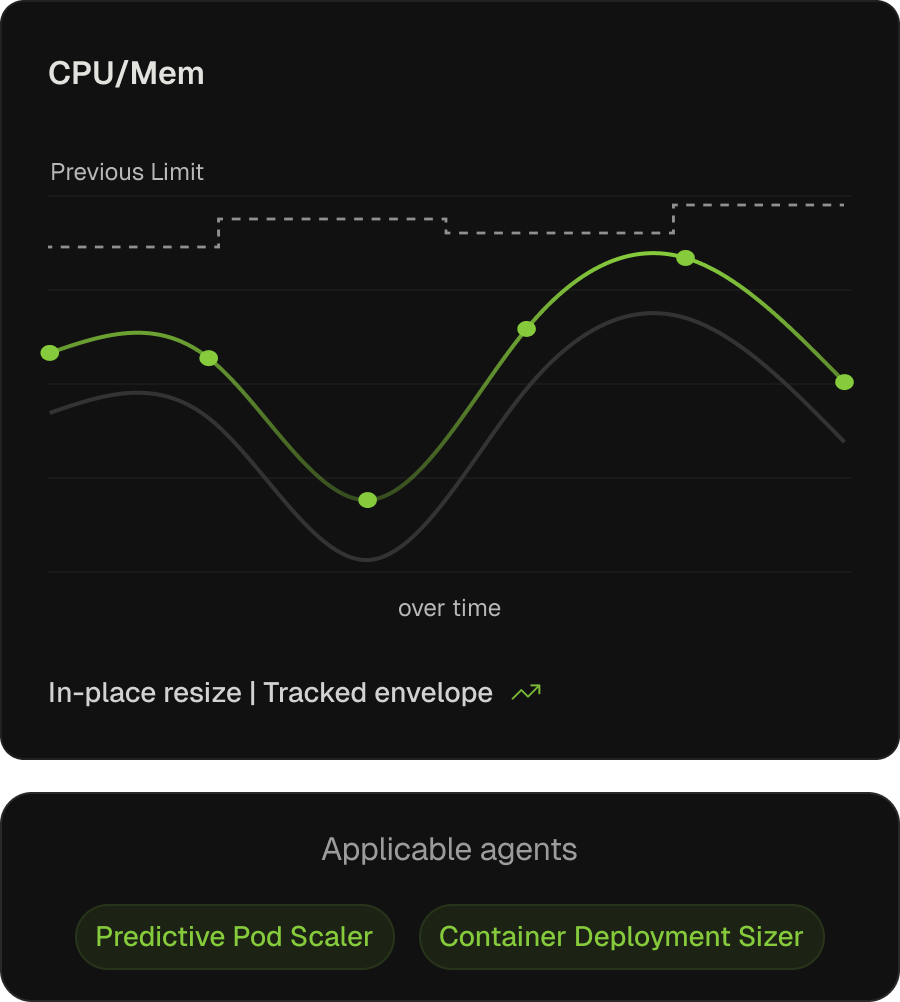
Request and limit specifications, kept in sync with workload reality.
On AKS, Azure Advisor produces sizing guidance and the open-source VPA can surface request recommendations — but neither closes the loop, so recommendations accumulate and rarely land. Kubex applies them continuously via mutating webhooks and in-place resize, leaving AKS-managed namespaces untouched.
Continuous request right-sizing
Tuned from learned utilization, freeing capacity the cluster autoscaler holds in reserve.
Limits prevent OOM and throttling
Shaped to actual peak behaviour, not template defaults.
Predictive scaling and new-workload sizing
Predictive Pod Scaler resizes ahead of learned patterns; Container Deployment Sizer drafts new specs via MCP.
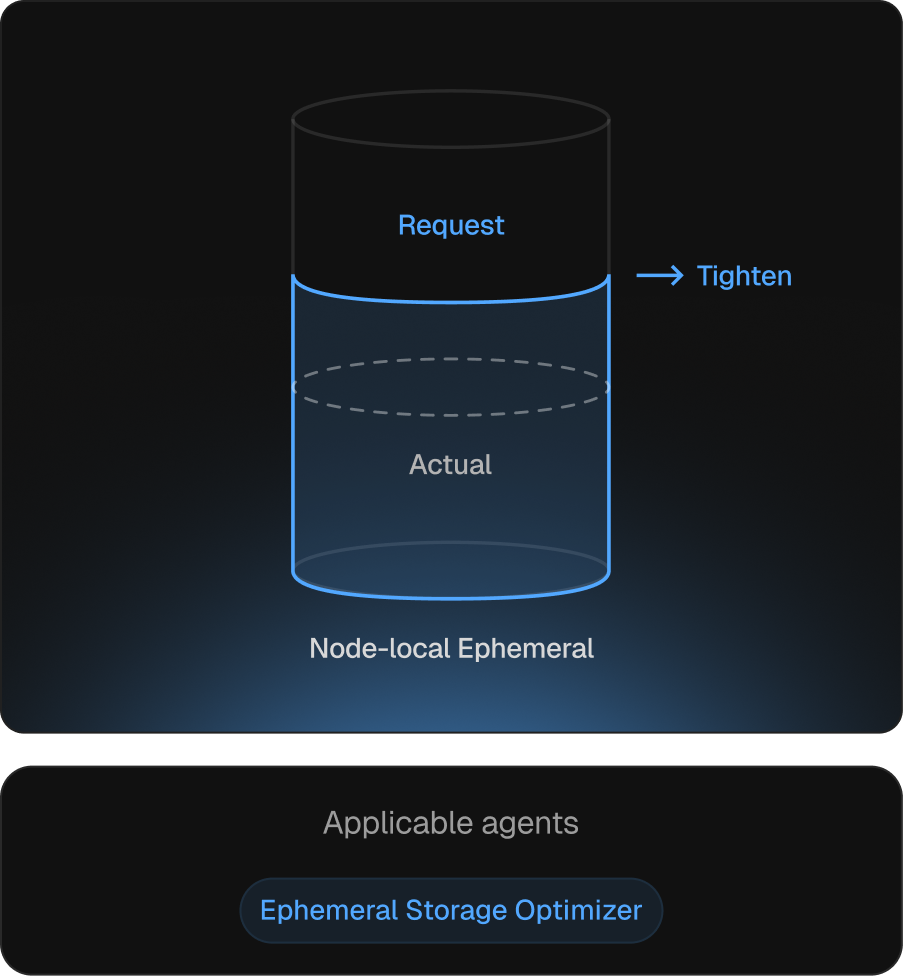
Local storage requests aligned to actual disk pressure.
Ephemeral storage is the resource discovered during incidents. On AKS, under-spec’d ephemeral-storage triggers disk-pressure evictions; over-spec’d caps pod density. Kubex tracks usage and adjusts requests via the same in-place path as CPU and memory.
Pressure-driven scheduling stays accurate
Requests reflect real disk consumption, not worst-case guesses.
Capacity restoration
Right-sized requests release headroom held against worst-case usage.
Disk-pressure evictions eliminated upstream
Requests track growth, so disk-pressure conditions never form.
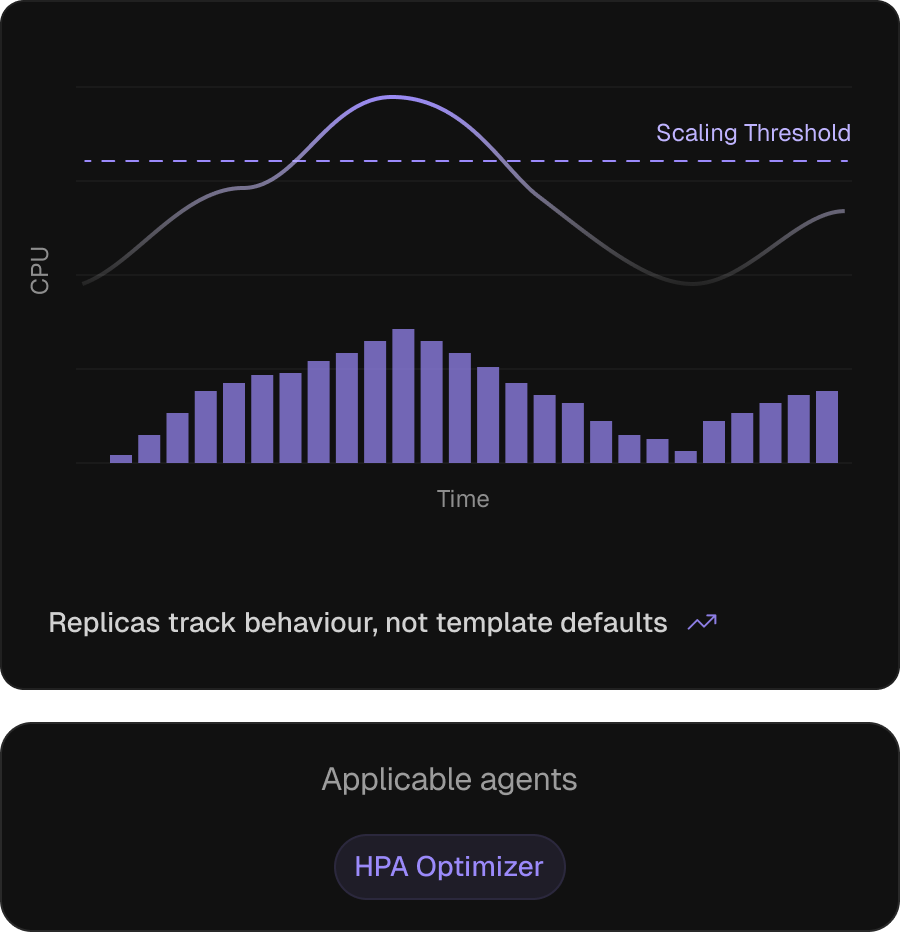
Horizontal autoscaling, configured from how the workload behaves.
On AKS, HPA (often paired with KEDA for event-sourced scaling) carries elasticity for most workloads, but keeping it correct is hard — thresholds inherit from templates, policies stay default, HPAs outlive their pod sizing. The HPA Optimizer recomputes thresholds, scale policies, and replica bounds against today’s workload.
Thresholds re-anchored after pod sizing
Recomputed when right-sizing shifts the request denominator.
Scale policies tuned to reaction time
Against observed behaviour, not Helm-chart defaults.
OOM and throttling shielded
Flags HPA settings that let pods hit throttling or OOM before scale-out.
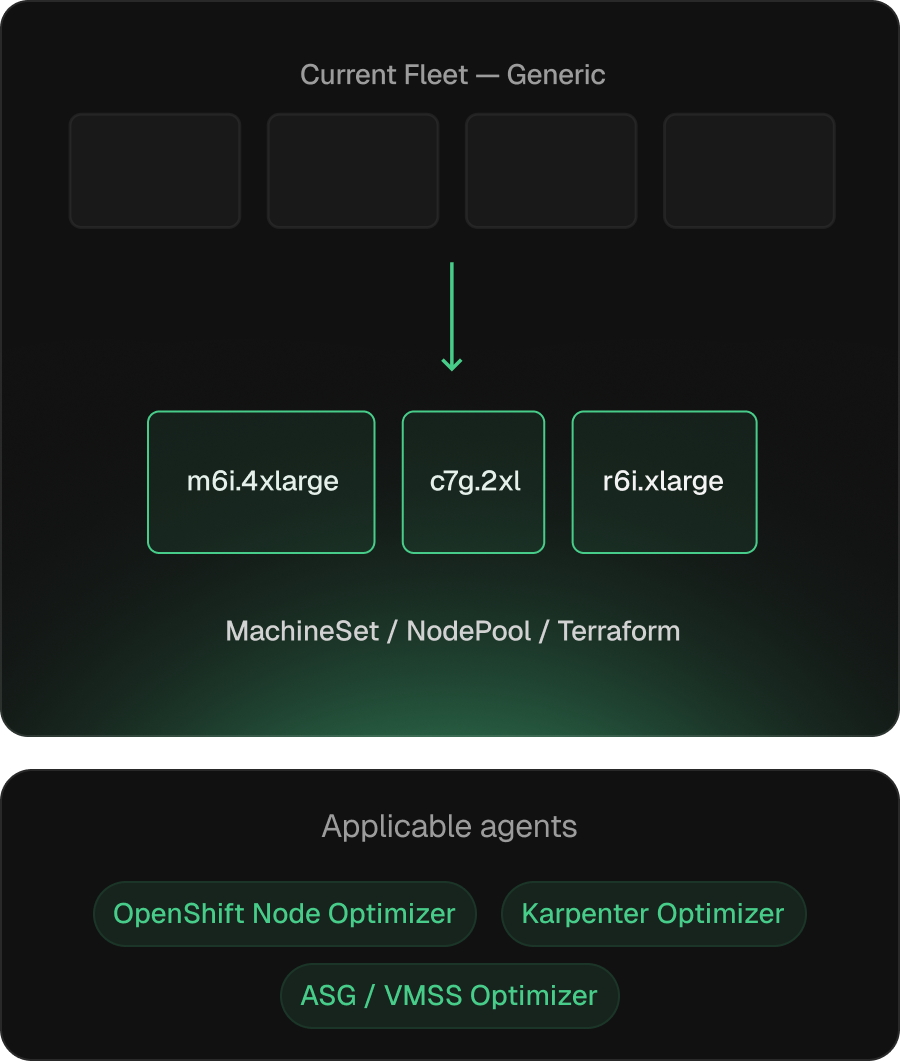
Node fleets that match the workload they actually run.
AKS node-pool specs drift from workload reality once pod sizing changes land. Kubex addresses this in two modes: simulation-based VM-SKU and scale-set parameter recommendations for VMSS-backed pools (via Terraform, az CLI, or GitOps), and NodePool specs via the Karpenter Optimizer on AKS (NAP) — with spot, ARM, and GPU candidates included.
Output is the artifact, not a recommendation
VMSS-backed node-pool specs, NodePools, or Terraform / Bicep diffs through existing change-management.
Aware of both AKS autoscaler modes
VMSS-backed node pools and Karpenter (NAP) each get the right primitive — VMSS scale-set parameters or NodePool requirements.
Continuous re-evaluation as pod sizing evolves
Recompute as pod requests change.
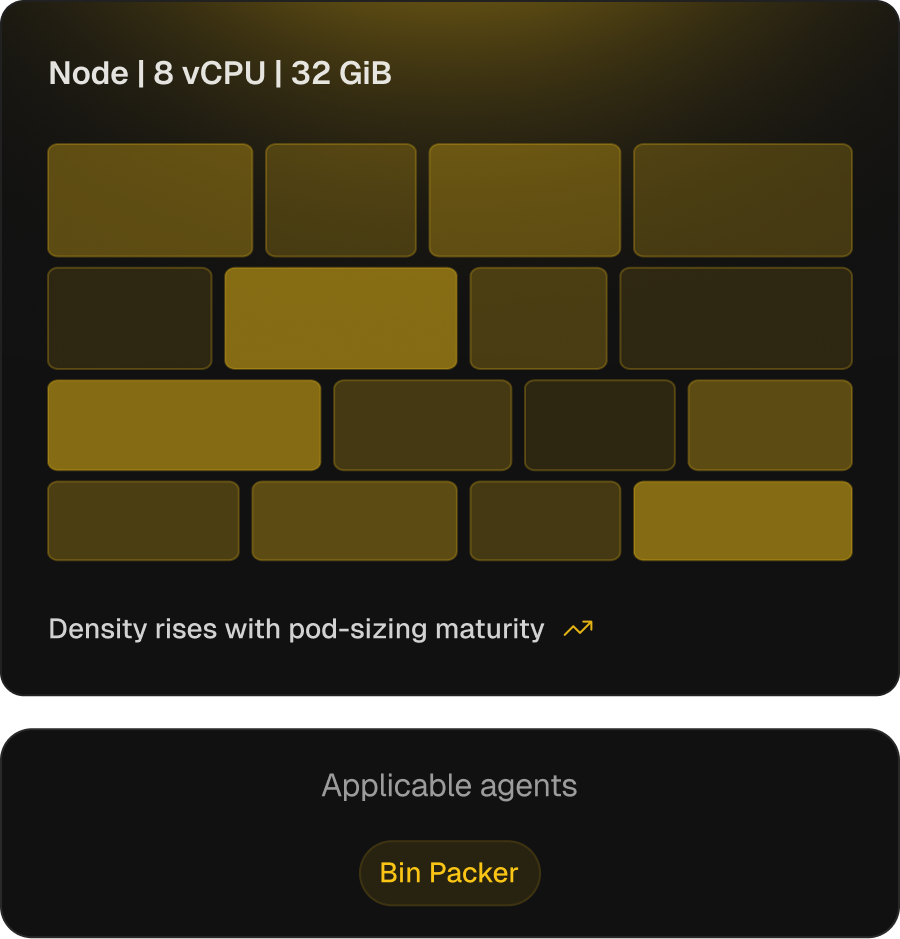
Higher pod density, with safety bounds that keep it usable.
On AKS, the cluster autoscaler and the scheduler’s bin-packing strategies (MostAllocated, RequestedToCapacityRatio) under-pack by default. Tuning them before right-sizing pods is the failure mode — overstacking, throttling, OOM. The Bin Packer ties density to pod-sizing maturity, raising it as sizing stabilises.
Max-pods and strategy per node type
Aligned to actual pod profile — MostAllocated / RequestedToCapacityRatio.
Consolidation thresholds move with pod-sizing maturity
AKS cluster-autoscaler scale-down delay and Karpenter consolidationPolicy auto-tuned from observed pod-sizing accuracy.
Per-pool consolidation profiles
System, GPU, and general pools each get their own aggressiveness — density gains don't churn pools that need to stay stable.
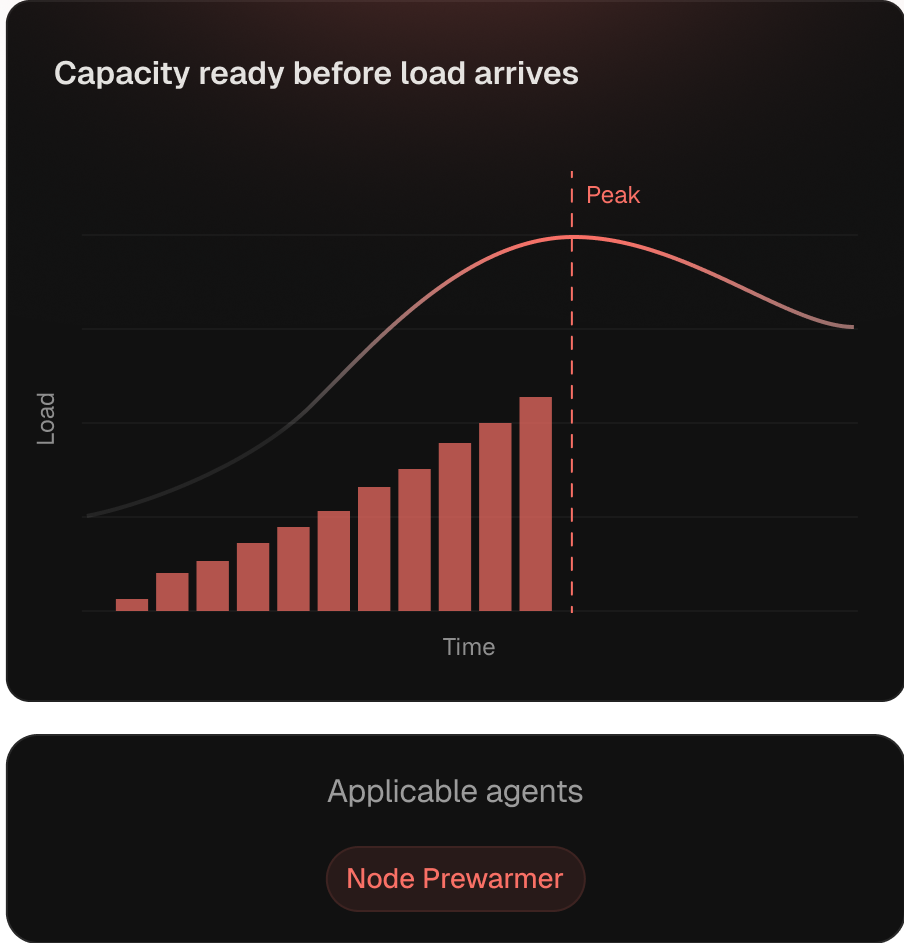
Capacity initialized before the load curve hits.
Reactive autoscaling adds nodes after pressure arrives — paid every day on daily-cyclical workloads. The Node Prewarmer provisions ahead of forecast from Kubex’s pattern models. Leverage peaks on GPU inference — CUDA pulls and model load dominate cold starts.
Predictive scheduling against learned patterns
Runs ahead of the daily load cycle, not after pressure.
GPU-aware pre-warming
CUDA pulls and model load accounted for, so inference SLOs aren't paid in warm-up.
Coordinated with bin packing
Pre-warm respects consolidation thresholds, so headroom doesn't fight stable-load density.
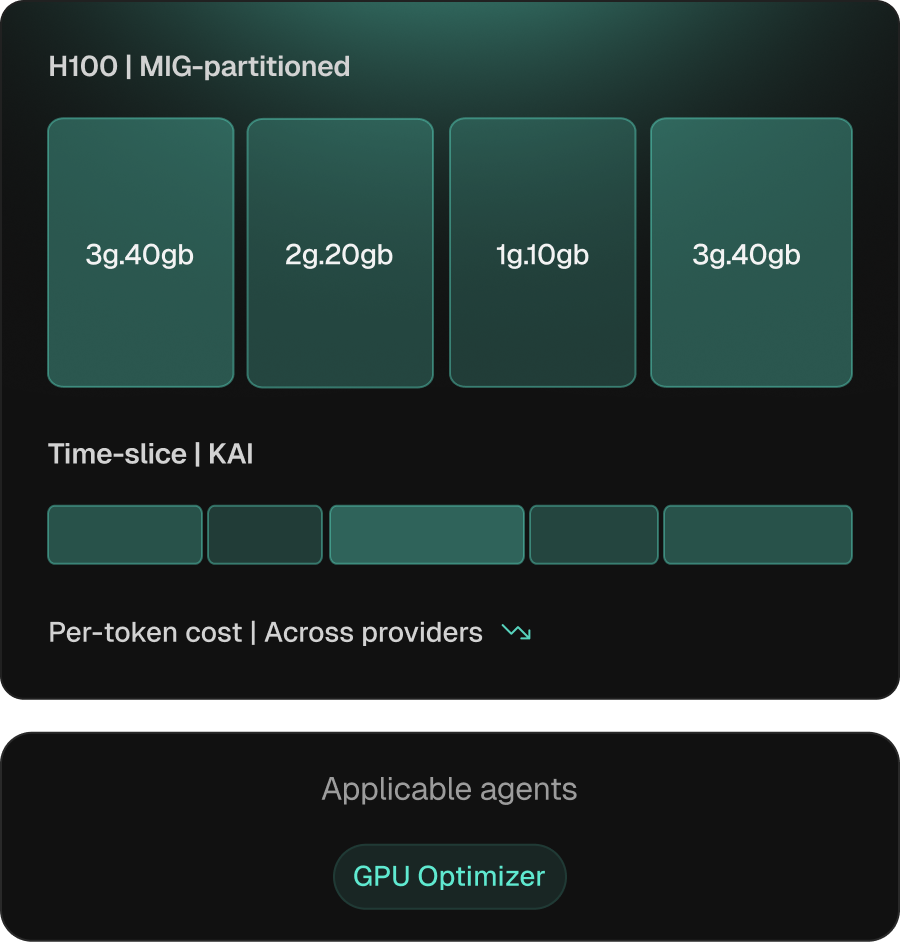
Inference and training, sized to the right GPU.
GPU workloads bring decisions CPU tooling doesn’t make — sharing strategy, partitioning, and SKU. On AKS Kubex covers all of it: time-slicing via NVIDIA KAI, MIG on Ampere/Hopper/Blackwell, SKU selection, and cross-provider analysis across Azure GPU SKUs (NC, ND, NV families), neoclouds, and adjacent CSPs.
Per-workload sharing strategy
MIG, time-slicing, or MPS — by isolation, flexibility, or memory profile.
SKU selection includes provider economics
Factor in benchmarks, availability, and pricing — not the local default.
Cross-provider price/performance
Workloads evaluated across CSPs, neoclouds, and on-prem — comparison, not auto-move.
AI Agents
Agentic AI combines market leading optimization intelligence with natural language interaction.
Talk to Kubex with natural-language queries about resources and fill the gaps common in SRE Agents
Navigate by asking for details about specific containers, nodes, or events
Enhanced sharing with interactive tables and deep links for export

See how Kubex looks against your AKS cluster.
A walk-through of the agent surface and change-management flow — on a cluster you actually run.