

During the Toronto KCD (Kubernetes Community Days), I attended an insightful talk on AI resource optimization that highlighted a staggering Gartner study: “AI infrastructure is adding $401 billion in new spending this year alone. Yet, real-world audits tell a much darker story, revealing that average GPU utilization in the enterprise is stuck at a dismal 5%”. While many people in the audience were shocked by that number, the data didn’t come as a surprise to us. At Kubex, this is a problem we identified and started tackling a long time ago.
Every CFO and enterprise AI leader is currently staring at this painful paradox. On one hand, securing premium silicon feels like a high-stakes race, and infrastructure line items are breaking budgets. On the other hand, for every dollar spent on raw computing power, 95 cents is essentially wasted on idle capacity.
In any other operational department, a 95% waste metric would trigger an immediate emergency, and entire teams would be overhauled. In AI infrastructure, this has quietly been tolerated as the baseline cost of staying competitive.
Low GPU utilization is one of the biggest hidden bottlenecks in LLM inference.
At Kubex, we look at this not as a hardware scarcity problem, but as a systems engineering failure. The root cause isn’t bad code or weak chips; it is a fundamental architectural mismatch between how Large Language Models calculate tokens and how standard Kubernetes clusters schedule resources.
To bridge this gap, our team at Kubex approached the problem from the infrastructure layer up. In a later blog post, I will pull back the curtain on how we solved this problem through what we call Disaggregated Intelligent Orchestration, an architecture that continuously aligns GPU resources with actual workload demand. But in order to be able to understand how we did this, we first need to understand how inference actually works under the hood.
Hence, the goal of this article is to take a quick dive into the intricacies of GPU inference mechanics and expose why low chip utilization is a structural architecture flaw rather than a hardware deficiency. By breaking down exactly what happens during a model’s processing cycle, we can see why standard deployment patterns fail, and lay the groundwork for how we must fundamentally rethink enterprise inference infrastructure to maximize silicon productivity.
The Core Bottleneck: Prefill vs. Decode
As a user when you interact with a large language model, the inference’s lifecycle is split into two radically different mathematical phases. These two phases run sequentially on the exact same chip, but they demand entirely different hardware resources.
Phase 1: The Prefill Phase – The Ingestion Stage
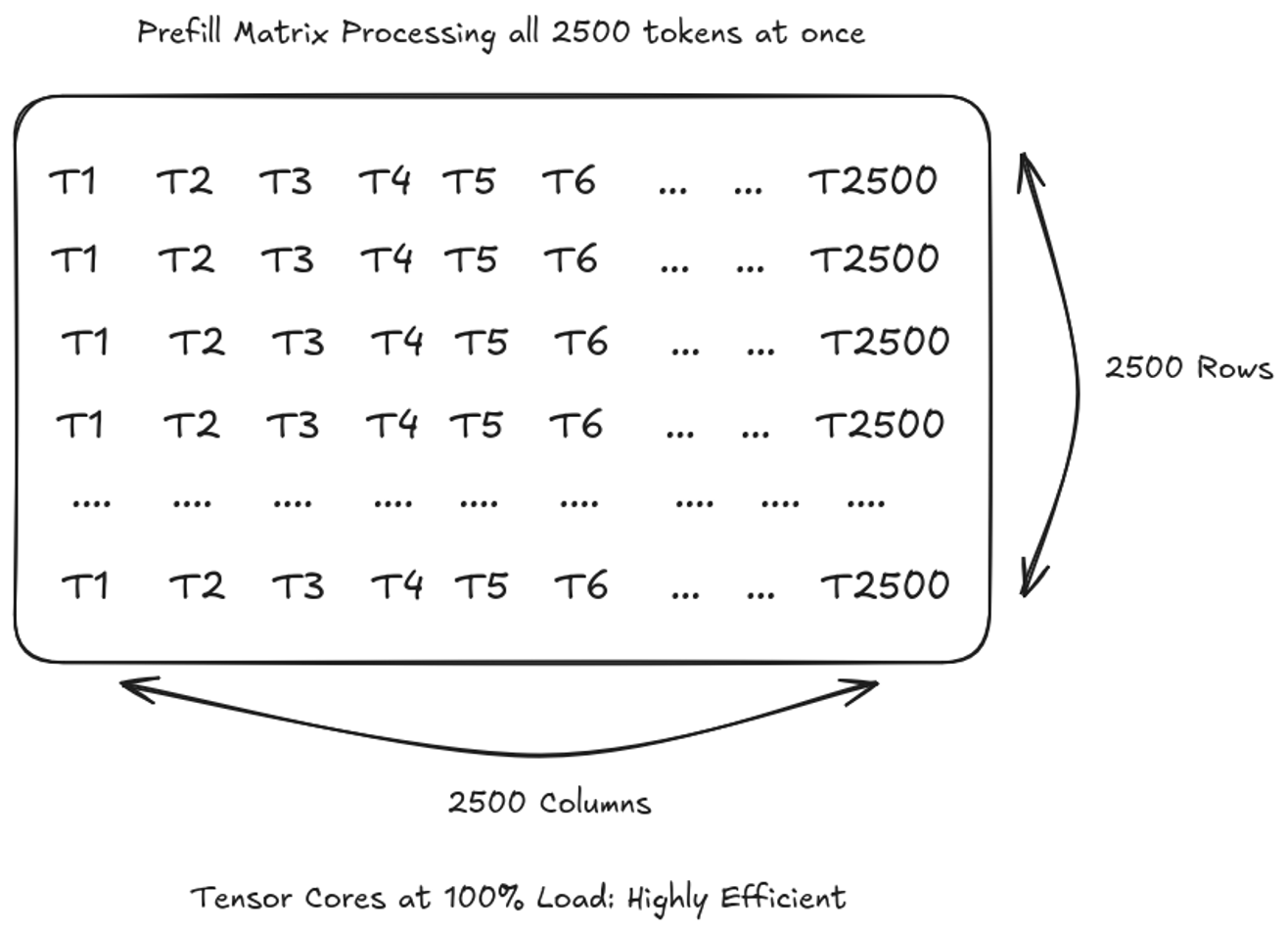
When you submit a prompt of 2,500 words, the model processes the entire input simultaneously to establish the initial context.
The Math: The GPU takes all 2500 tokens and runs a massive parallel matrix multiplication 2500 x 2500 to understand the relationships between every single word at the exact same time.
This phase is highly compute-bound. The GPU’s Tensor Cores work at their maximum. They scale across parallel hardware to utilize almost 100% of the GPU’s processing power to crunch the prompt as fast as possible.
This phase is crucial because it’s the one that dictates the TTFT (Time to First Token).
Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch LLM Inference: https://arxiv.org/html/2503.08311v2
Phase 2: The Decode Phase – The Generation Stage
The moment the model finishes processing the prompt and generates its very first response word, the math changes completely. Large language models cannot generate an entire paragraph at once; they are autoregressive, meaning they generate text sequentially, one token at a time.
The Math: To generate the next word, the GPU takes the previous word, feeds it back to the model as an input, and calculates the next one. Instead of the massive square matrix, the GPU is now calculating a single row of data (1 x Context Length).
This phase does not require computation power and is heavily memory-bandwidth-bound. Because a single row requires almost zero raw mathematical calculation, the GPU’s Tensor Cores drop to near-zero utilization. Now, the chip spends its time waiting for the memory bus to fetch the KV Cache; The digital notebook stored in memory that holds the context of the previous 2500 words plus every new token generated.
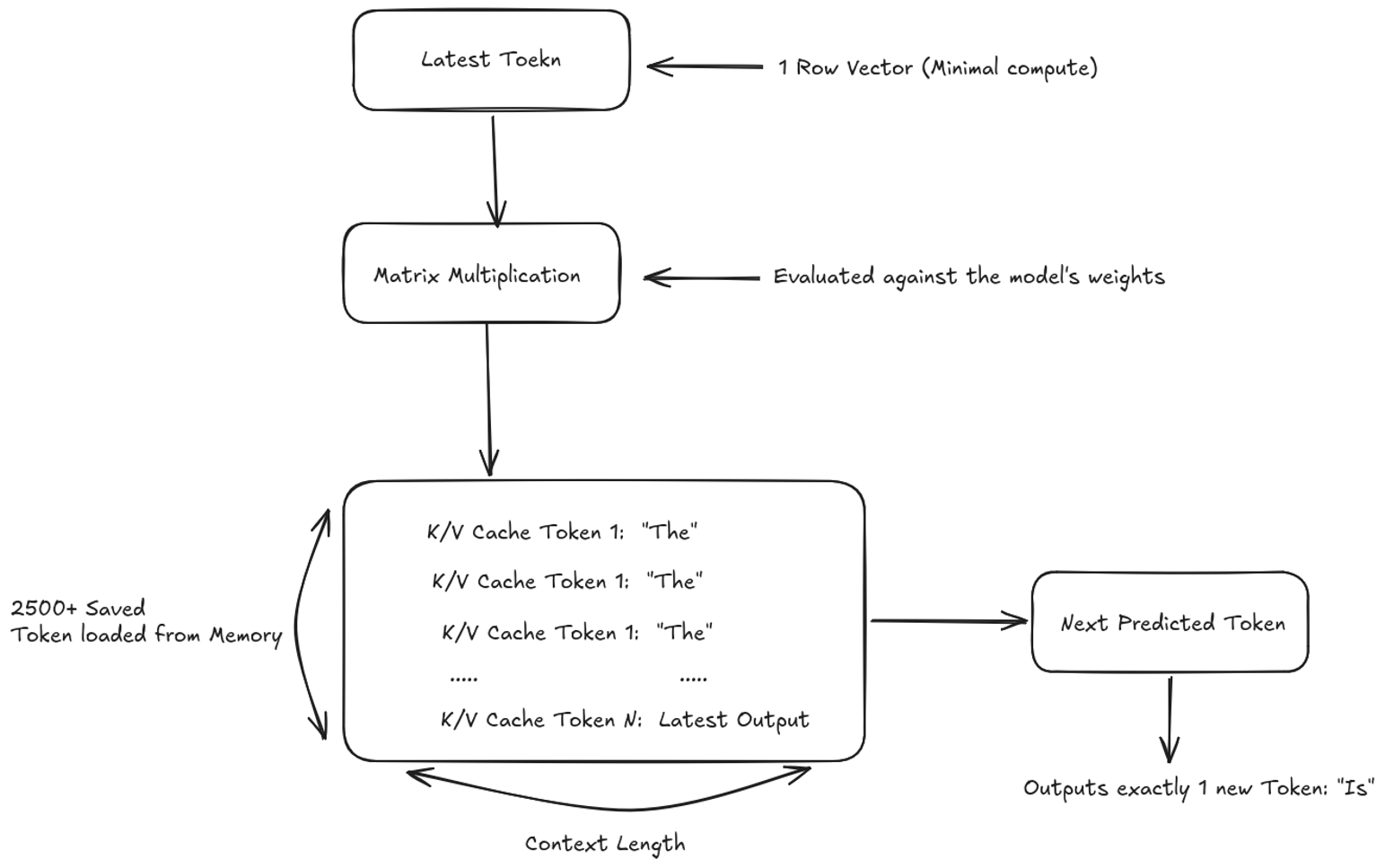
Because the GPU must wait to retrieve the entire history from memory just to calculate that one row, the generation loops go as below:
[Cycle 1] Generate 1st Word:
INPUT: [Read 2500 Prompt Tokens from Memory]
MATH: 1 Row Calculation (Tensor Cores 95% Idle)
OUTPUT: “The”
[Cycle 2] Generate 2nd Word:
INPUT: [Read 2500 Prompt Tokens + “The” from Memory]
MATH: 1 Row Calculation (Tensor Cores 95% Idle)
OUTPUT: “Inference”
[Cycle 3] Generate 3rd Word:
INPUT: [Read 2500 Prompt Tokens + “The” + “Inference” from Memory]
MATH: 1 Row Calculation (Tensor Cores 95% Idle)
OUTPUT: “Paradox”
This word-by-word sequential cycle illustrates the memory bus bottleneck perfectly: the bottleneck isn’t raw processing power; it’s the time spent waiting on RAM.
In this article, we took a deep dive into the intricacies of LLM inference to expose why low GPU utilization is a fundamental architectural issue, not a hardware deficiency. In our next post, I will explain exactly how the Kubex team approaches this challenge and how we solve it using Disaggregated Intelligent Orchestration.


