

In the modern cloud infrastructure landscape, we don’t have a data problem; we have an actionable interpretation gap. Engineering teams are often drowning in metrics that describe a crisis without providing a clear path to remediation. Traditional FinOps, SRE, and DevOps work has become a reactive loop of dashboard-watching and manual firefighting.
While AI is often pitched as the magic fix, there is a fundamental difference between a generic chatbot and a specialized copilot agent that understands the context of your environment and works proactively alongside you.
This post is the first in a series where we pull back the curtain on the AI infrastructure we are building at Kubex. We’re starting with the philosophy and architecture that turn a mine of raw analytics into an intelligent, agentic experience.
Grounding Reasoning in Reality
At Kubex, we are not building another “AI wrapper”. It’s rather a system that knows the fundamental context of your infrastructure topology, your historical performance, and your cost dynamics.
The team spent years building the backbone foundation of our analytics platform that excels in resource right-sizing automation, traffic and workload forecasting, and cost savings.
This is where the Agentic AI Platform comes into the game as an additional layer that sits on top of the deterministic engine. Hence, it doesn’t have to determine answers from first principles, and risk hallucination, because it queries the analytics for the ground truth. By combining generative intent with mathematical certainty, we ensure that every action is safe, verified, and constrained by robust guardrails.
The agentic platform doesn’t replace the execution layer; it leverages the existing automation platform to fuel an ecosystem of autonomous and semi-autonomous agents in order to achieve deterministic results.
The Connective Tissue: Why is MCP a Pillar component?
As a first step in bootstrapping our AI infrastructure, we embarked on a journey to build the Kubex MCP Server, to allow our AI to actually “see” and “hear” what our analytics engine is saying. Seen under this angle, the Kubex Model Context Protocol became a necessity, and we built it as a pillar component of our system.
As we’re speaking, the Kubex MCP Server is not only giving the Kubex Agentic Services a precise real-time lens into clusters’ data but also allowing integrations from outside the Kubex ecosystem.
For the technical deep dive on how we built the Kubex MCP Server, check out this awesome blog post by Richard Bilson, our Head of AI Engineering; /blog-we-built-an-mcp-server.
The Cephalopod Operating System
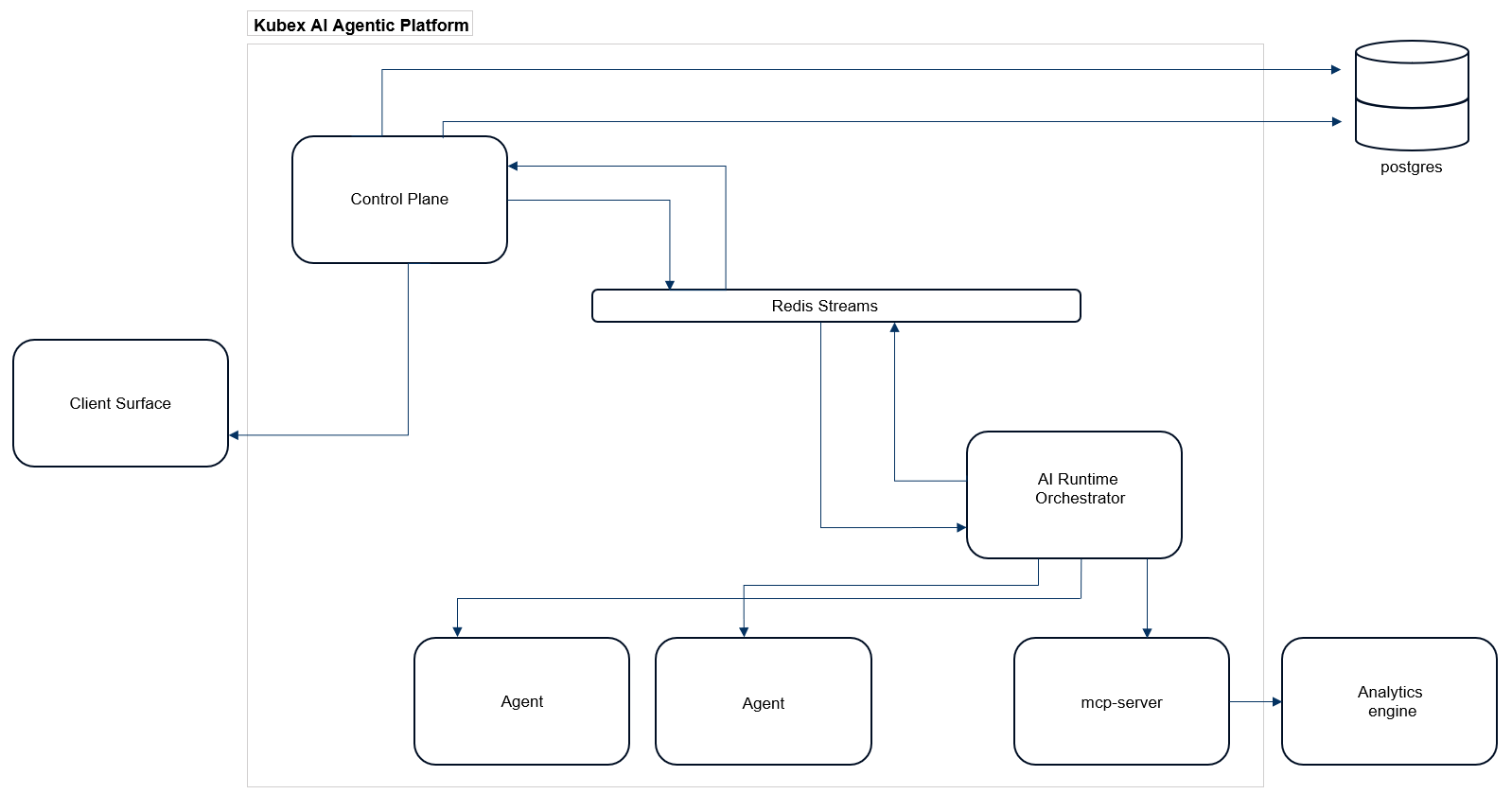
To build a system capable of handling the scale at which we operate within our clients’ enterprise infrastructure, we engineered an agentic architecture that is fully distributed by default. We mirrored the decentralized nervous system of an octopus to ensure that intelligence is not trapped in a central bottleneck and allow many parts of the infrastructure to operate in complete autarky without degrading the collective intelligence of the platform.
To maintain this coordination at scale, we structured the platform into three levels of abstraction:
- Client Surface: The primary interactive touchpoint where the human-to-agent collaboration begins (web-based UI, API clients, Terminal UI).
- Control Plane: The middle layer functions as a local coordination hub. It translates complex global instructions into actionable distributed tasks, managing the flow of data across different regions of the infrastructure.
- AI Runtime Orchestrator: At the execution edge where agents operate with the independence of an octopus arm, this is the reasoning engine. The Brain that orchestrates the agentic part, tool execution, and the translation of intent into action.
Further in the article, we will lift the curtain on the Agentic Automation Engine, one of the core engines that leverages services from both the Control Plane and the AI Runtime Orchestrator layers.
The Nervous System: Redis Streams
One of the secrets of the Kubex Agentic AI architecture is our commitment to keep things simple and avoid reinventing the wheel. Hence, to make this distributed system feel seamless, we chose Redis Streams.
By utilizing a streaming architecture for inter-service communication, we gain several vital advantages:
- Decoupling: Services can produce and consume events at their own pace. If a reasoning loop takes longer, the rest of the system remains responsive.
- Persistent Intent: Streams provide a durable history of messages. This means if a service restarts, it can pick up right where it left off without losing the user’s context.
- Real-time Scaling: We can spin up more consumers in the AI Runtime Orchestrator Layer during peak traffic without reconfiguring the Services Layer.
- Backpressure Handling: Consumer groups let us absorb traffic spikes gracefully. Slow consumers don’t overwhelm fast producers, and work is redistributed automatically.
- Fault Isolation: A failure in one consumer doesn’t cascade. Messages remain in the stream until successfully processed, keeping errors contained.
- Observability by Design: Stream offsets and pending entries give us built-in insight into system health, lag, and throughput without extra instrumentation.
- Replayability: Because events are retained, we can replay streams to debug issues, rebuild state, or test new consumers against real production traffic.
The Automation Engine: Adaptive Intelligence at Scale
A powerful aspect of this architecture is how we handle recurring intelligence. We designed a generic strike force system that any agent can leverage to operate with full or semi-autonomy. We structure it around three main acts, borrowing jargon of theatre, to keep the system predictable and observable. This modularity allows the system to scale its operational impact without adding complexity to individual agents.
- The Scheduler (Intent Act):
This serves as the universal intelligence layer for agents to schedule, subscribe, or set reminders. It interprets high-level goals and maps them into structured, recurring requirements. Because this system is generic, any agent can use it to maintain long-term objectives without needing to manage the underlying logic themselves. - The Executor (Execution Act):
This is the engine that actually runs the tasks. Operating independently of the AI runtime Orchestrator, it acts as the “heart” of the set-it-and-forget-it capability. It ensures that once an agent has subscribed to a goal, the execution is triggered precisely when due, providing the reliable strike force necessary for autonomous operations. - The Universal Delivery Framework (Information Act):
This ensures that agents can communicate with the outside world and that the outcome is delivered to the right person / place at the right time, whether it’s a silent background optimization or a high-priority Slack alert. It integrates seamlessly with multiple channels including email, chat platforms, webhooks, and in-product notifications, allowing each action to surface where it is most effective.
The Agentic Automation Engine enables the system to take proactive, deterministic actions without compromising its intelligence or autonomy.
Over time, it will power scheduled jobs, background workflows, and fully autonomous agents that operate independently while remaining aligned with system policies and constraints.
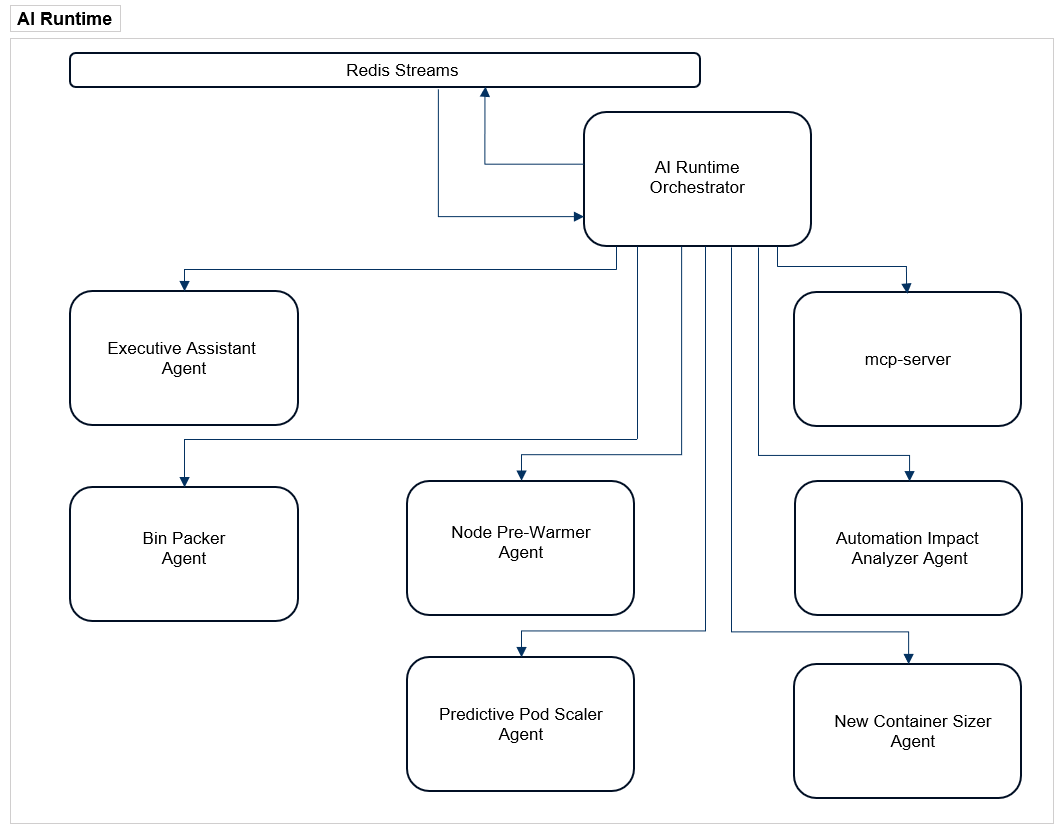
A Fleet of Specialized Agents: The arms with Mini Brains
The foundation of the Kubex agentic architecture allowed us to start deploying a fleet of specialized agents, each focused on solving a specific infrastructure challenge while always updating with the latest progress for complete transparency. This fleet of dedicated expert is evolving every day and below is the list of the special purpose agents that are currently operating within the Kubex Agentic platform:
- The Personal Assistant: This agent is responsible for keeping the user informed about system activity, setting reminders for recurring events, and continuously synthesizing objectives into clear priorities to ensure nothing falls through the cracks.
- The Automation Impact Analyzer: This agent autonomously assesses how resource adjustments affect clusters’ health and cost to ensure every change is backed by data and surfaced clearly to the user.
- The Predictive Pod Scaler: This agent anticipates traffic surges and proactively manages vertical scaling of the requests of the container, doing in-place resizing as loads increase and decrease to maintain performance without manual intervention.
- The Node Pre-warmer: This agent observes the system’s activity and orchestrates infrastructure readiness by predicting spikes and initializing nodes before capacity bottlenecks can occur.
- The New Container Sizer: This agent analyzes existing containers and clusters them into size bands, so it can smartly determine an optimal starting point for the next one before it ever runs.
- The Bin-Packer: This agent functions as the system’s efficiency architect, continuously analyzing real-time resource utilization to determine the optimal placement for every workload. By mapping active pods and services against available node capacity, it dynamically reshapes the cluster to maximize density, effectively eliminating stranded resources and reducing infrastructure overhead.
The Workflow of Approval: These agents do not act in isolation. Each agent is designed to analyze the current state, plan an optimized path, and submit that plan for approval. The approval process can be performed either by a higher rank agent (approved by the user) or by a human operator. Once the plan is approved, it is passed to the underlying automation system for direct execution. In both scenarios, whether using a higher rank agent (approved by the user) or a Human in the Loop, we ensure that while intelligence is autonomous, the final control remains in the user’s hands.
Safety and the Road to Autonomy
When you give an AI power over production infrastructure, safety isn’t an afterthought; it is the core. Our architecture enforces strict multi-tenant context across every stream, service, and tool execution. The boundaries between users and environments are immutable. In a future article, we will dive deeper into how the Control Plane manages multiple databases at runtime, specifically detailing how each client is assigned a completely separate persistence layer to enforce strict security and preserve a total separation of concerns.
We are also intentional about staged autonomy. Today, the platform focuses on surfacing deep insights and streamlining complex analysis. While our roadmap includes fully autonomous actions like bin-packing or node pre-warming, we currently use the AI to complement the human operator. We provide the intelligence and the “ready-to-fire” actions, but the user keeps the ultimate control.
What’s Next?
This foundation allows us to progressively roll out advanced features like closed-loop bin-packing optimization and node pre-warming based on traffic patterns. We have built a decentralized nervous system for intelligent infrastructure. In the coming posts of this series, we will dive deeper into each component and discuss the neat capabilities of the system.


